思考并回答以下问题:
11丨YAML:Kubernetes世界里的通用语
思考并回答以下问题:
- “声明式”与“命令式”完全相反,不关心具体的过程,更注重结果。我们不需要“教”计算机该怎么做,只要告诉它一个目标状态,它自己就会想办法去完成任务,相比起来自动化、智能化程度更高。YAML是什么式?
Kubernetes“弃用Docker”是怎么回事?
什么是CRI
在2016年底的1.5版里,Kubernetes引入了一个新的接口标准:CRI,Container Runtime Interface。
CRI采用了ProtoBuffer和gPRC,规定kubelet该如何调用容器运行时去管理容器和镜像,但这是一套全新的接口,和之前的Docker调用完全不兼容。
Kubernetes意思很明显,就是不想再绑定在Docker上了,允许在底层接入其他容器技术(比如rkt、kata等),随时可以把Docker“踢开”。
但是这个时候Docker已经非常成熟,而且市场的惯性也非常强大,各大云厂商不可能一下子就把Docker全部替换掉。所以Kubernetes也只能同时提供一个“折中”方案,在kubelet和Docker中间加入一个“适配器”,把Docker的接口转换成符合CRI标准的接口:
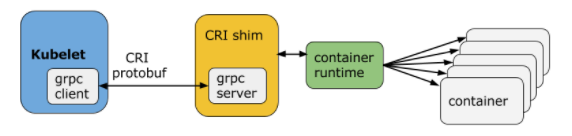
因为这个“适配器”夹在kubelet和Docker之间,所以就被形象地称为是“shim”,也就是“垫片”的意思。
有了CRI和shim,虽然Kubernetes还使用Docker作为底层运行时,但也具备了和Docker解耦的条件,从此就拉开了“弃用Docker”这场大戏的帷幕。
什么是containerd
Docker没有“坐以待毙”,而是采取了“断臂求生”的策略,推动自身的重构,把原本单体架构的Docker Engine拆分成了多个模块,其中的Docker daemon部分就捐献给了CNCF,形成了containerd。
containerd作为CNCF的托管项目,自然是要符合CRI标准的。但Docker出于自己诸多原因的考虑,它只是在Docker Engine里调用了containerd,外部的接口仍然保持不变,也就是说还不与CRI兼容。
由于Docker的“固执己见”,这时Kubernetes里就出现了两种调用链:
- 第一种是用CRI接口调用docker shim,然后docker shim调用Docker,Docker再走containerd去操作容器。
- 第二种是用CRI接口直接调用containerd去操作容器。
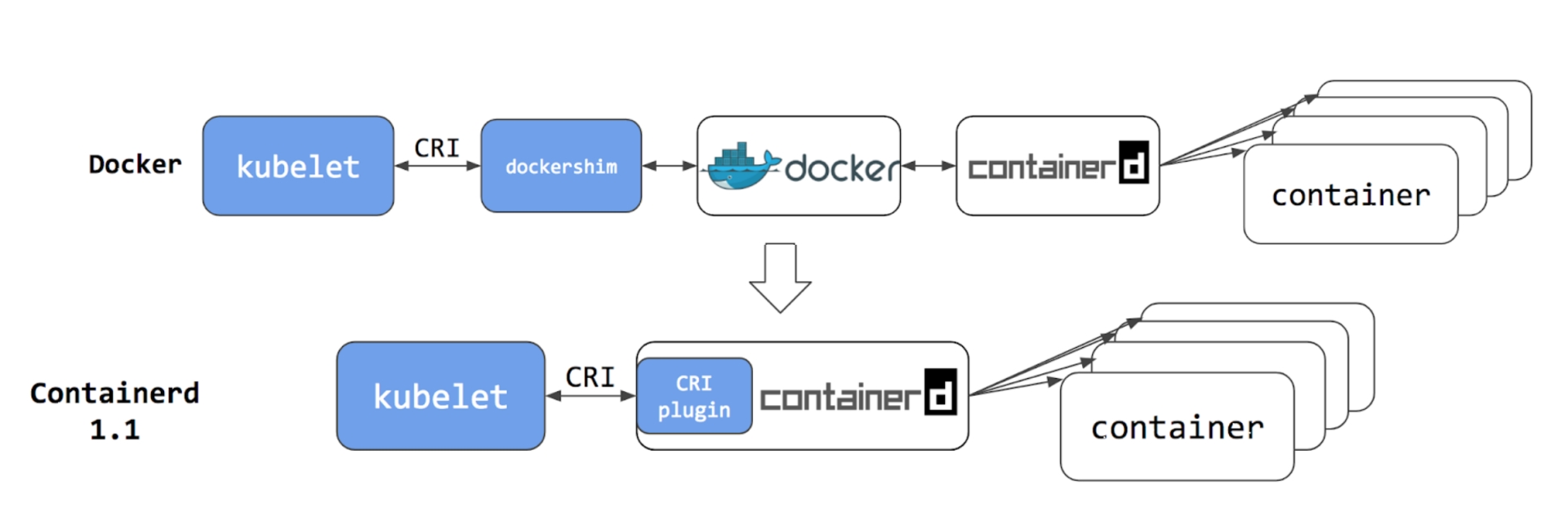
显然,由于都是用containerd来管理容器,所以这两种调用链的最终效果是完全一样的,但是第二种方式省去了docker shim和Docker Engine两个环节,更加简洁明了,损耗更少,性能也会提升一些。
正式“弃用Docker”
如果你理解了前面讲的CRI和containerd这两个项目,就会知道Kubernetes实际上只是“弃用了docker shim”这个小组件,也就是说把docker shim移出了kubelet,并不是“弃用了Docker”这个软件产品。
所以,“弃用Docker”对Kubernetes和Docker来说都不会有什么太大的影响,因为他们两个都早已经把下层都改成了开源的containerd,原来的Docker镜像和容器仍然会正常运行,唯一的变化就是Kubernetes绕过了Docker,直接调用Docker内部的containerd而已。
这个关系你可以参考下面的这张图来理解:
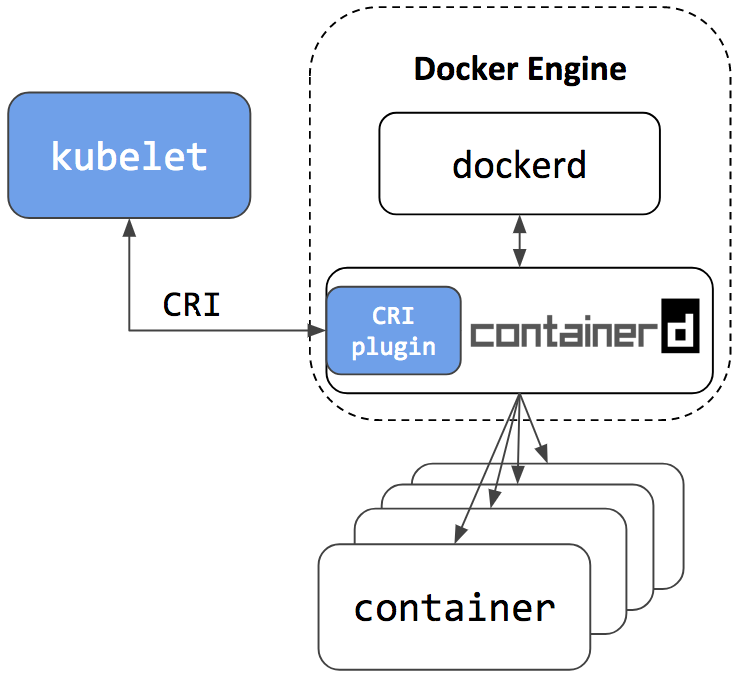
当然,影响也不是完全没有。如果Kubernetes直接使用containerd来操纵容器,那么它就是一个与Docker独立的工作环境,彼此都不能访问对方管理的容器和镜像。换句话说,使用命令docker ps就看不到在Kubernetes里运行的容器了。
这对有的人来说可能需要稍微习惯一下,改用新的工具crictl,不过用来查看容器、镜像的子命令还是一样的,比如ps、images等等,适应起来难度不大(但如果我们一直用kubectl来管理Kubernetes的话,这就是没有任何影响了)。
Kubernetes在1.24版本把docker shim的代码从kubelet里删掉了。
Docker的未来
虽然Kubernetes已经不再包含docker shim,但Docker公司却把这部分代码接管了过来,另建了一个叫cri-docker的项目,作用也是一样的,把Docker Engine适配成CRI接口,这样kubelet就又可以通过它来操作Docker了,就仿佛是一切从未发生过。
10丨自动化的运维管理:探究Kubernetes工作机制的奥秘
思考并回答以下问题:
- 容器是什么?容器是软件,是应用,是进程。服务器是什么?服务器是硬件,是CPU、内存、硬盘、网卡。那么,既可以管理软件,也可以管理硬件,这样的东西应该是什么?这就是一个操作系统(Operating System)!从某种角度来看,Kubernetes可以说是一个集群级别的操作系统,主要功能就是资源管理和作业调度。但Kubernetes不是运行在单机上管理单台计算资源和进程,而是运行在多台服务器上管理几百几千台的计算资源,以及在这些资源上运行的上万上百万的进程,规模要大得多。怎么理解?
- Kubernetes采用了现今流行的“控制面/数据面”(Control Plane/Data Plane)架构,集群里的计算机被称为“节点”(Node),可以是实机也可以是虚机,少量的节点用作控制面来执行集群的管理维护工作,其他的大部分节点都被划归数据面,用来跑业务应用。怎么理解?
- 控制面的节点在Kubernetes里叫做Master Node,一般简称为Master,它是整个集群里最重要的部分,可以说是Kubernetes的大脑和心脏。数据面的节点叫做Worker Node,一般就简称为Worker或者Node,相当于Kubernetes的手和脚,在Master的指挥下干活。怎么理解?
- Node的数量非常多,构成了一个资源池,Kubernetes就在这个池里分配资源,调度应用。因为资源被“池化”了,所以管理也就变得比较简单,可以在集群中任意添加或者删除节点。怎么理解?
- Master和Node的划分不是绝对的。当集群的规模较小,工作负载较少的时候,Master也可以承担Node的工作,就像我们搭建的minikube环境,它就只有一个节点,这个节点既是Master又是Node。怎么理解?
- Kubernetes的节点内部也具有复杂的结构,是由很多的模块构成的,这些模块又可以分成组件(Component)和插件(Addon)两类。这两个有什么区别?
- apiserver是联络员,etcd是配置管理员,scheduler是部署人员,controller-manager是监控运维人员。怎么理解?
kubectl get pod -n kube-system是干嘛用的?- kubelet是Node上的一个“小管家”,kube-proxy是专职的“小邮差”,container-runtime是真正干活的“苦力”。怎么理解?
- kubelet和kubectl有什么区别?
09丨走近云原生:如何在本机搭建小巧完备的Kubernetes环境
思考并回答以下问题:
- 容器技术的核心概念是容器、镜像、仓库。为什么?
- 容器编排就是这些容器之上的管理、调度工作。怎么理解?
- 容器技术只解决了应用的打包、安装问题,面对复杂的生产环境就束手无策了,解决之道就是容器编排,它能够组织管理各个应用容器之间的关系,让它们顺利地协同运行。怎么理解?
- Kubernetes就是一个生产级别的容器编排平台和集群管理系统,不仅能够创建、调度容器,还能够监控、管理服务器。怎么理解?
- minikube只能够搭建Kubernetes环境,要操作Kubernetes,还需要另一个专门的客户端工具“kubectl”。怎么理解?
kubectl run ngx --image=nginx:alpine命令执行之后可以看到,在Kubernetes集群里就有了一个名字叫ngx的Pod正在运行,是什么意思?kubectl get pod是什么意思?- 所谓的“云”,现在就指的是Kubernetes,那么“云原生”的意思就是应用的开发、部署、运维等一系列工作都要向Kubernetes看齐,使用容器、微服务、声明式API等技术,保证应用的整个生命周期都能够在Kubernetes环境里顺利实施,不需要附加额外的条件。怎么理解?
07丨实战演练:玩转Docker
思考并回答以下问题:
- 镜像是容器的静态形式,它把应用程序连同依赖的操作系统、配置文件、环境变量等等都打包到了一起,因而能够在任何系统上运行,免除了很多部署运维和平台迁移的麻烦。怎么理解?
- 镜像内部由多个层(Layer)组成,每一层都是一组文件,多个层会使用Union FS技术合并成一个文件系统供容器使用。这种细粒度结构的好处是相同的层可以共享、复用,节约磁盘存储和网络传输的成本,也让构建镜像的工作变得更加容易。怎么理解?