思考并回答以下问题:
Channel是Go语言内建的first-class类型,也是Go语言与众不同的特性之一。Go语言的Channel设计精巧简单,以至于也有人用其它语言编写了类似Go风格的Channel库,比如docker/libchan、tylertreat/chan,但是并不像Go语言一样把Channel内置到了语言规范中。从这一点,你也可以看出来,Channel的地位在编程语言中的地位之高,比较罕见。
所以,这节课,我们就来学习下Channel。
Channel的发展
要想了解Channel这种Go编程语言中的特有的数据结构,我们要追溯到CSP模型,学习一下它的历史,以及它对Go创始人设计Channel类型的影响。
CSP是Communicating Sequential Process的简称,中文直译为通信顺序进程,或者叫做交换信息的循序进程,是用来描述并发系统中进行交互的一种模式。
CSP最早出现于计算机科学家Tony Hoare在1978年发表的论文中(你可能不熟悉Tony Hoare这个名字,但是你一定很熟悉排序算法中的Quicksort算法,他就是Quicksort算法的作者,图灵奖的获得者)。最初,论文中提出的CSP版本在本质上不是一种进程演算,而是一种并发编程语言,但之后又经过了一系列的改进,最终发展并精炼出CSP的理论。CSP允许使用进程组件来描述系统,它们独立运行,并且只通过消息传递的方式通信。
就像Go的创始人之一Rob Pike所说的:“每一个计算机程序员都应该读一读Tony Hoare 1978年的关于CSP的论文。”他和Ken Thompson在设计Go语言的时候也深受此论文的影响,并将CSP理论真正应用于语言本身(Russ Cox专门写了一篇文章记录这个历史),通过引入Channel这个新的类型,来实现CSP的思想。
Channel类型是Go语言内置的类型,你无需引入某个包,就能使用它。虽然Go也提供了传统的并发原语,但是它们都是通过库的方式提供的,你必须要引入sync包或者atomic包才能使用它们,而Channel就不一样了,它是内置类型,使用起来非常方便。
Channel和Go的另一个独特的特性goroutine一起为并发编程提供了优雅的、便利的、与传统并发控制不同的方案,并演化出很多并发模式。接下来,我们就来看一看Channel的应用场景。
Channel的应用场景
首先,我想先带你看一条Go语言中流传很广的谚语:
Don’t communicate by sharing memory, share memory by communicating.
这是Rob Pike在2015年的一次Gopher会议中提到的一句话,虽然有一点绕,但也指出了使用Go语言的哲学,我尝试着来翻译一下:“执行业务处理的goroutine不要通过共享内存的方式通信,而是要通过Channel通信的方式分享数据。”
“communicate by sharing memory”和“share memory by communicating”是两种不同的并发处理模式。“communicate by sharing memory”是传统的并发编程处理方式,就是指,共享的数据需要用锁进行保护,goroutine需要获取到锁,才能并发访问数据。
“share memory by communicating”则是类似于CSP模型的方式,通过通信的方式,一个goroutine可以把数据的“所有权”交给另外一个goroutine(虽然Go中没有“所有权”的概念,但是从逻辑上说,你可以把它理解为是所有权的转移)。
从Channel的历史和设计哲学上,我们就可以了解到,Channel类型和基本并发原语是有竞争关系的,它应用于并发场景,涉及到goroutine之间的通讯,可以提供并发的保护,等等。
综合起来,我把Channel的应用场景分为五种类型。这里你先有个印象,这样你可以有目的地去学习Channel的基本原理。下节课我会借助具体的例子,来带你掌握这几种类型。
1,数据交流:当作并发的buffer或者queue,解决生产者-消费者问题。多个goroutine可以并发当作生产者(Producer)和消费者(Consumer)。
2,数据传递:一个goroutine将数据交给另一个goroutine,相当于把数据的拥有权(引用)托付出去。
3,信号通知:一个goroutine可以将信号(closing、closed、dataready等)传递给另一个或者另一组goroutine。
4,任务编排:可以让一组goroutine按照一定的顺序并发或者串行的执行,这就是编排的功能。
5,锁:利用Channel也可以实现互斥锁的机制。
下面,我们来具体学习下Channel的基本用法。
Channel基本用法
你可以往Channel中发送数据,也可以从Channel中接收数据,所以,Channel类型(为了说起来方便,我们下面都把Channel叫做chan)分为只能接收、只能发送、既可以接收又可以发送三种类型。下面是它的语法定义:1
ChannelType = ( "chan" | "chan" "<-" | "<-" "chan" ) ElementType .
相应地,Channel的正确语法如下:1
2
3chan string // 可以发送接收string
chan<- struct{} // 只能发送struct{}
<-chan int // 只能从chan接收int
我们把既能接收又能发送的chan叫做双向的chan,把只能发送和只能接收的chan叫做单向的chan。其中,“<-”表示单向的chan,如果你记不住,我告诉你一个简便的方法:这个箭头总是射向左边的,元素类型总在最右边。如果箭头指向chan,就表示可以往chan中塞数据;如果箭头远离chan,就表示chan会往外吐数据。
chan中的元素是任意的类型,所以也可能是chan类型,我来举个例子,比如下面的chan类型也是合法的:1
2
3
4chan<- chan int
chan<- <-chan int
<-chan <-chan int
chan (<-chan int)
可是,怎么判定箭头符号属于哪个chan呢?其实,“<-”有个规则,总是尽量和左边的chan结合(The <- operator associates with the leftmost chan possible),因此,上面的定义和下面的使用括号的划分是一样的:1
2
3
4chan<- (chan int) // <- 和第一个chan结合
chan<- (<-chan int) // 第一个<-和最左边的chan结合,第二个<-和左边第二个chan结合
<-chan (<-chan int) // 第一个<-和最左边的chan结合,第二个<-和左边第二个chan结合
chan (<-chan int) // 因为括号的原因,<-和括号内第一个chan结合
通过make,我们可以初始化一个chan,未初始化的chan的零值是nil。你可以设置它的容量,比如下面的chan的容量是9527,我们把这样的chan叫做buffered chan;如果没有设置,它的容量是0,我们把这样的chan叫做unbuffered chan。1
make(chan int, 9527)
如果chan中还有数据,那么,从这个chan接收数据的时候就不会阻塞,如果chan还未满(“满”指达到其容量),给它发送数据也不会阻塞,否则就会阻塞。unbuffered chan只有读写都准备好之后才不会阻塞,这也是很多使用unbuffered chan时的常见Bug。
还有一个知识点需要你记住:nil是chan的零值,是一种特殊的chan,对值是nil的chan的发送接收调用者总是会阻塞。
下面,我来具体给你介绍几种基本操作,分别是发送数据、接收数据,以及一些其它操作。学会了这几种操作,你就能真正地掌握Channel的用法了。
1,发送数据
往chan中发送一个数据使用“ch<-”,发送数据是一条语句:1
ch <- 2000
这里的ch是chan int类型或者是chan <-int。
2,接收数据
从chan中接收一条数据使用“<-ch”,接收数据也是一条语句:1
2
3x := <-ch // 把接收的一条数据赋值给变量x
foo(<-ch) // 把接收的一个的数据作为参数传给函数
<-ch // 丢弃接收的一条数据
这里的ch类型是chan T或者<-chan T。
接收数据时,还可以返回两个值。第一个值是返回的chan中的元素,很多人不太熟悉的是第二个值。第二个值是bool类型,代表是否成功地从chan中读取到一个值,如果第二个参数是false,chan已经被close而且chan中没有缓存的数据,这个时候,第一个值是零值。所以,如果从chan读取到一个零值,可能是sender真正发送的零值,也可能是closed的并且没有缓存元素产生的零值。
3,其它操作
Go内建的函数close、cap、len都可以操作chan类型:close会把chan关闭掉,cap返回chan的容量,len返回chan中缓存的还未被取走的元素数量。
send和recv都可以作为select语句的case clause,如下面的例子:1
2
3
4
5
6
7
8
9
10func main() {
var ch = make(chan int, 10)
for i := 0; i < 10; i++ {
select {
case ch <- i:
case v := <-ch:
fmt.Println(v)
}
}
}
chan还可以应用于for-range语句中,比如:1
2
3for v := range ch {
fmt.Println(v)
}
或者是忽略读取的值,只是清空chan:1
2for range ch {
}
好了,到这里,Channel的基本用法,我们就学完了。下面我从代码实现的角度分析chan类型的实现。毕竟,只有掌握了原理,你才能真正地用好它。
Channel的实现原理
接下来,我会给你介绍chan的数据结构、初始化的方法以及三个重要的操作方法,分别是send、recv和close。通过学习Channel的底层实现,你会对Channel的功能和异常情况有更深的理解。
chan数据结构
chan类型的数据结构如下图所示,它的数据类型是runtime.hchan。
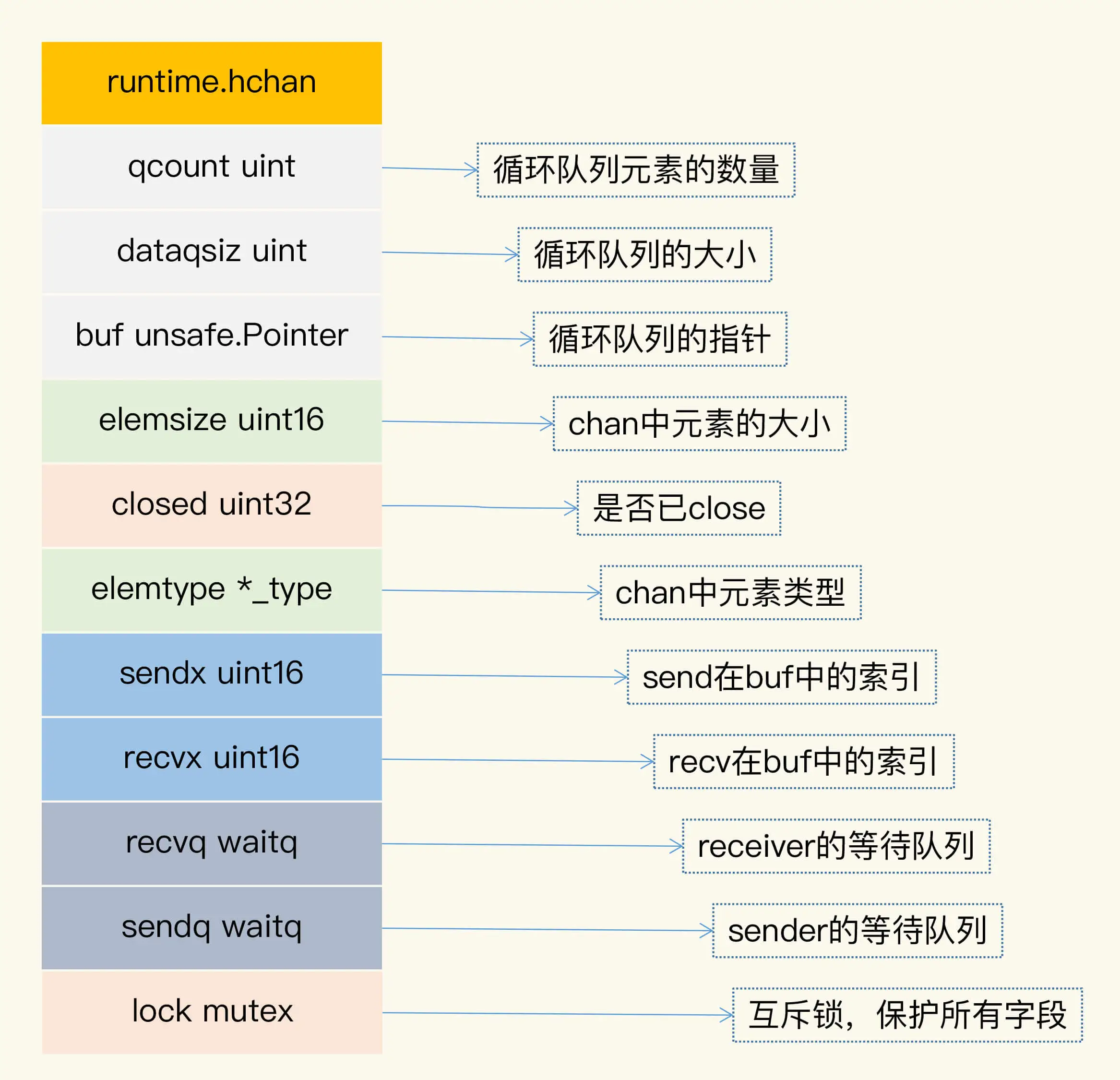
下面我来具体解释各个字段的意义。
- qcount:代表chan中已经接收但还没被取走的元素的个数。内建函数len可以返回这个字段的值。
- dataqsiz:队列的大小。chan使用一个循环队列来存放元素,循环队列很适合这种生产者-消费者的场景(我很好奇为什么这个字段省略size中的e)。
- buf:存放元素的循环队列的buffer。
- elemtype和elemsize:chan中元素的类型和size。因为chan一旦声明,它的元素类型是固定的,即普通类型或者指针类型,所以元素大小也是固定的。
- sendx:处理发送数据的指针在buf中的位置。一旦接收了新的数据,指针就会加上elemsize,移向下一个位置。buf的总大小是elemsize的整数倍,而且buf是一个循环列表。
- recvx:处理接收请求时的指针在buf中的位置。一旦取出数据,此指针会移动到下一个位置。
- recvq:chan是多生产者多消费者的模式,如果消费者因为没有数据可读而被阻塞了,就会被加入到recvq队列中。
- sendq:如果生产者因为buf满了而阻塞,会被加入到sendq队列中。
初始化
Go在编译的时候,会根据容量的大小选择调用makechan64,还是makechan。
下面的代码是处理makechan的逻辑,它会决定是使用makechan还是makechan64来实现chan的初始化:
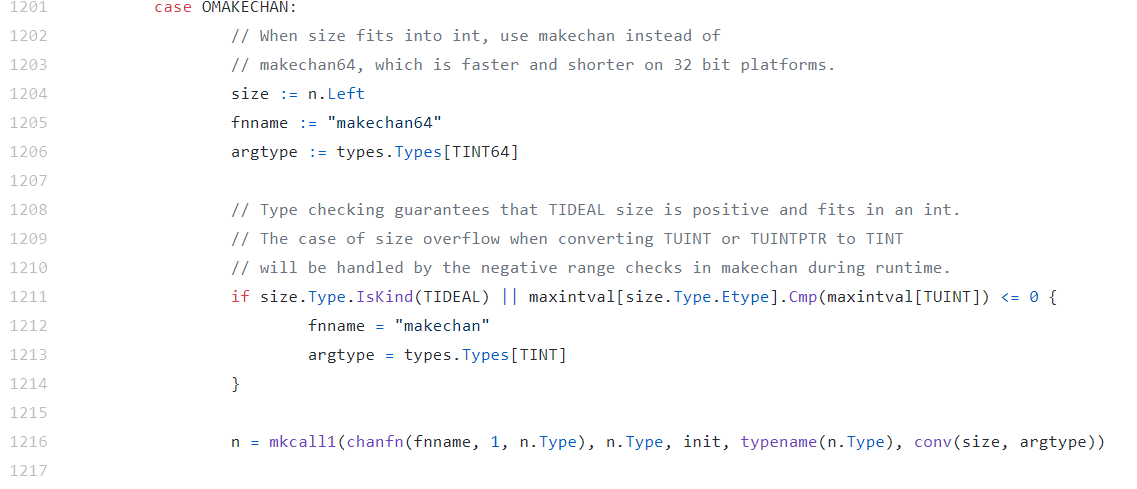
我们只关注makechan就好了,因为makechan64只是做了size检查,底层还是调用makechan实现的。makechan的目标就是生成hchan对象。
那么,接下来,就让我们来看一下makechan的主要逻辑。主要的逻辑我都加上了注释,它会根据chan的容量的大小和元素的类型不同,初始化不同的存储空间:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32func makechan(t *chantype, size int) *hchan {
elem := t.elem
// 略去检查代码
mem, overflow := math.MulUintptr(elem.size, uintptr(size))
//
var c *hchan
switch {
case mem == 0:
// chan的size或者元素的size是0,不必创建buf
c = (*hchan)(mallocgc(hchanSize, nil, true))
c.buf = c.raceaddr()
case elem.ptrdata == 0:
// 元素不是指针,分配一块连续的内存给hchan数据结构和buf
c = (*hchan)(mallocgc(hchanSize+mem, nil, true))
// hchan数据结构后面紧接着就是buf
c.buf = add(unsafe.Pointer(c), hchanSize)
default:
// 元素包含指针,那么单独分配buf
c = new(hchan)
c.buf = mallocgc(mem, elem, true)
}
// 元素大小、类型、容量都记录下来
c.elemsize = uint16(elem.size)
c.elemtype = elem
c.dataqsiz = uint(size)
lockInit(&c.lock, lockRankHchan)
return c
}
最终,针对不同的容量和元素类型,这段代码分配了不同的对象来初始化hchan对象的字段,返回hchan对象。
send
Go在编译发送数据给chan的时候,会把send语句转换成chansend1函数,chansend1函数会调用chansend,我们分段学习它的逻辑:1
2
3
4
5
6
7
8
9
10
11
12
13
14func chansend1(c *hchan, elem unsafe.Pointer) {
chansend(c, elem, true, getcallerpc())
}
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
// 第一部分
if c == nil {
if !block {
return false
}
gopark(nil, nil, waitReasonChanSendNilChan, traceEvGoStop, 2)
throw("unreachable")
}
......
}
最开始,第一部分是进行判断:如果chan是nil的话,就把调用者goroutine park(阻塞休眠),调用者就永远被阻塞住了,所以,第11行是不可能执行到的代码。1
2
3
4// 第二部分,如果chan没有被close,并且chan满了,直接返回
if !block && c.closed == 0 && full(c) {
return false
}
第二部分的逻辑是当你往一个已经满了的chan实例发送数据时,并且想不阻塞当前调用,那么这里的逻辑是直接返回。chansend1方法在调用chansend的时候设置了阻塞参数,所以不会执行到第二部分的分支里。1
2
3
4
5
6// 第三部分,chan已经被close的情景
lock(&c.lock) // 开始加锁
if c.closed != 0 {
unlock(&c.lock)
panic(plainError("send on closed channel"))
}
第三部分显示的是,如果chan已经被close了,再往里面发送数据的话会panic。1
2
3
4
5
6// 第四部分,从接收队列中出队一个等待的receiver
if sg := c.recvq.dequeue(); sg != nil {
//
send(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true
}
第四部分,如果等待队列中有等待的receiver,那么这段代码就把它从队列中弹出,然后直接把数据交给它(通过memmove(dst,src,t.size)),而不需要放入到buf中,速度可以更快一些。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16// 第五部分,buf还没满
if c.qcount < c.dataqsiz {
qp := chanbuf(c, c.sendx)
if raceenabled {
raceacquire(qp)
racerelease(qp)
}
typedmemmove(c.elemtype, qp, ep)
c.sendx++
if c.sendx == c.dataqsiz {
c.sendx = 0
}
c.qcount++
unlock(&c.lock)
return true
}
第五部分说明当前没有receiver,需要把数据放入到buf中,放入之后,就成功返回了。1
2
3
4
5
6
7// 第六部分,buf满。
// chansend1不会进入if块里,因为chansend1的block=true
if !block {
unlock(&c.lock)
return false
}
......
第六部分是处理buf满的情况。如果buf满了,发送者的goroutine就会加入到发送者的等待队列中,直到被唤醒。这个时候,数据或者被取走了,或者chan被close了。
recv
在处理从chan中接收数据时,Go会把代码转换成chanrecv1函数,如果要返回两个返回值,会转换成chanrecv2,chanrecv1函数和chanrecv2会调用chanrecv。我们分段学习它的逻辑:1
2
3
4
5
6
7
8
9
10
11
12
13
14func chansend1(c *hchan, elem unsafe.Pointer) {
chansend(c, elem, true, getcallerpc())
}
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
// 第一部分
if c == nil {
if !block {
return false
}
gopark(nil, nil, waitReasonChanSendNilChan, traceEvGoStop, 2)
throw("unreachable")
}
......
}
chanrecv1和chanrecv2传入的block参数的值是true,都是阻塞方式,所以我们分析chanrecv的实现的时候,不考虑block=false的情况。
第一部分是chan为nil的情况。和send一样,从nilchan中接收(读取、获取)数据时,调用者会被永远阻塞。1
2
3
4// 第二部分,如果chan没有被close,并且chan满了,直接返回
if !block && c.closed == 0 && full(c) {
return false
}
第二部分你可以直接忽略,因为不是我们这次要分析的场景。1
2
3
4
5
6// 第三部分,chan已经被close的情景
lock(&c.lock) // 开始加锁
if c.closed != 0 {
unlock(&c.lock)
panic(plainError("send on closed channel"))
}
第三部分是chan已经被close的情况。如果chan已经被close了,并且队列中没有缓存的元素,那么返回true、false。1
2
3
4
5
6// 第四部分,从接收队列中出队一个等待的receiver
if sg := c.recvq.dequeue(); sg != nil {
//
send(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true
}
第四部分是处理buf满的情况。这个时候,如果是unbuffer的chan,就直接将sender的数据复制给receiver,否则就从队列头部读取一个值,并把这个sender的值加入到队列尾部。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23// 第五部分, 没有等待的sender, buf中有数据
if c.qcount > 0 {
qp := chanbuf(c, c.recvx)
if ep != nil {
typedmemmove(c.elemtype, ep, qp)
}
typedmemclr(c.elemtype, qp)
c.recvx++
if c.recvx == c.dataqsiz {
c.recvx = 0
}
c.qcount--
unlock(&c.lock)
return true, true
}
if !block {
unlock(&c.lock)
return false, false
}
// 第六部分, buf中没有元素,阻塞
......
第五部分是处理没有等待的sender的情况。这个是和chansend共用一把大锁,所以不会有并发的问题。如果buf有元素,就取出一个元素给receiver。
第六部分是处理buf中没有元素的情况。如果没有元素,那么当前的receiver就会被阻塞,直到它从sender中接收了数据,或者是chan被close,才返回。
close
通过close函数,可以把chan关闭,编译器会替换成closechan方法的调用。
下面的代码是closechan的主要逻辑。如果chan为nil,close会panic;如果chan已经closed,再次close也会panic。否则的话,如果chan不为nil,chan也没有closed,就把等待队列中的sender(writer)和receiver(reader)从队列中全部移除并唤醒。
下面的代码就是closechan的逻辑:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40func closechan(c *hchan) {
if c == nil { // chan为nil, panic
panic(plainError("close of nil channel"))
}
lock(&c.lock)
if c.closed != 0 {// chan已经closed, panic
unlock(&c.lock)
panic(plainError("close of closed channel"))
}
c.closed = 1
var glist gList
// 释放所有的reader
for {
sg := c.recvq.dequeue()
......
gp := sg.g
......
glist.push(gp)
}
// 释放所有的writer (它们会panic)
for {
sg := c.sendq.dequeue()
......
gp := sg.g
......
glist.push(gp)
}
unlock(&c.lock)
for !glist.empty() {
gp := glist.pop()
gp.schedlink = 0
goready(gp, 3)
}
}
掌握了Channel的基本用法和实现原理,下面我再来给你讲一讲容易犯的错误。你一定要认真看,毕竟,这些可都是帮助你避坑的。
使用Channel容易犯的错误
根据2019年第一篇全面分析Go并发Bug的论文,那些知名的Go项目中使用Channel所犯的Bug反而比传统的并发原语的Bug还要多。主要有两个原因:一个是,Channel的概念还比较新,程序员还不能很好地掌握相应的使用方法和最佳实践;第二个是,Channel有时候比传统的并发原语更复杂,使用起来很容易顾此失彼。
使用Channel最常见的错误是panic和goroutine泄漏。
首先,我们来总结下会panic的情况,总共有3种:
- close为nil的chan;
- send已经close的chan;
- close已经close的chan。
goroutine泄漏的问题也很常见,下面的代码也是一个实际项目中的例子:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16func process(timeout time.Duration) bool {
ch := make(chan bool)
go func() {
// 模拟处理耗时的业务
time.Sleep((timeout + time.Second))
ch <- true // block
fmt.Println("exit goroutine")
}()
select {
case result := <-ch:
return result
case <-time.After(timeout):
return false
}
}
在这个例子中,process函数会启动一个goroutine,去处理需要长时间处理的业务,处理完之后,会发送true到chan中,目的是通知其它等待的goroutine,可以继续处理了。
我们来看一下第10行到第15行,主goroutine接收到任务处理完成的通知,或者超时后就返回了。这段代码有问题吗?
如果发生超时,process函数就返回了,这就会导致unbuffered的chan从来就没有被读取。我们知道,unbufferedchan必须等reader和writer都准备好了才能交流,否则就会阻塞。超时导致未读,结果就是子goroutine就阻塞在第7行永远结束不了,进而导致goroutine泄漏。
解决这个Bug的办法很简单,就是将unbufferedchan改成容量为1的chan,这样第7行就不会被阻塞了。
Go的开发者极力推荐使用Channel,不过,这两年,大家意识到,Channel并不是处理并发问题的“银弹”,有时候使用并发原语更简单,而且不容易出错。所以,我给你提供一套选择的方法:
1,共享资源的并发访问使用传统并发原语;
2,复杂的任务编排和消息传递使用Channel;
3,消息通知机制使用Channel,除非只想signal一个goroutine,才使用Cond;
4,简单等待所有任务的完成用WaitGroup,也有Channel的推崇者用Channel,都可以;
5,需要和Select语句结合,使用Channel;
6,需要和超时配合时,使用Channel和Context。
它们踩过的坑
接下来,我带你围观下知名Go项目的Channel相关的Bug。
etcdissue6857是一个程序hang住的问题:在异常情况下,没有往chan实例中填充所需的元素,导致等待者永远等待。具体来说,Status方法的逻辑是生成一个chanStatus,然后把这个chan交给其它的goroutine去处理和写入数据,最后,Status返回获取的状态信息。
不幸的是,如果正好节点停止了,没有goroutine去填充这个chan,会导致方法hang在返回的那一行上(下面的截图中的第466行)。解决办法就是,在等待statuschan返回元素的同时,也检查节点是不是已经停止了(done这个chan是不是close了)。
当前的etcd的代码就是修复后的代码,如下所示:
其实,我感觉这个修改还是有问题的。问题就在于,如果程序执行了466行,成功地把c写入到Status待处理队列后,执行到第467行时,如果停止了这个节点,那么,这个Status方法还是会阻塞在第467行。你可以自己研究研究,看看是不是这样。
etcdissue5505虽然没有任何的Bug描述,但是从修复内容上看,它是一个往已经close的chan写数据导致panic的问题。
etcdissue11256是因为unbufferedchangoroutine泄漏的问题。TestNodeProposeAddLearnerNode方法中一开始定义了一个unbuffered的chan,也就是applyConfChan,然后启动一个子goroutine,这个子goroutine会在循环中执行业务逻辑,并且不断地往这个chan中添加一个元素。TestNodeProposeAddLearnerNode方法的末尾处会从这个chan中读取一个元素。
这段代码在for循环中就往此chan中写入了一个元素,结果导致TestNodeProposeAddLearnerNode从这个chan中读取到元素就返回了。悲剧的是,子goroutine的for循环还在执行,阻塞在下图中红色的第851行,并且一直hang在那里。
这个Bug的修复也很简单,只要改动一下applyConfChan的处理逻辑就可以了:只有子goroutine的for循环中的主要逻辑完成之后,才往applyConfChan发送一个元素,这样,TestNodeProposeAddLearnerNode收到通知继续执行,子goroutine也不会被阻塞住了。
etcdissue9956是往一个已close的chan发送数据,其实它是grpc的一个bug(grpcissue2695),修复办法就是不close这个chan就好了:
总结
chan的值和状态有多种情况,而不同的操作(send、recv、close)又可能得到不同的结果,这是使用chan类型时经常让人困惑的地方。
为了帮助你快速地了解不同状态下各种操作的结果,我总结了一个表格,你一定要特别关注下那些panic的情况,另外还要掌握那些会block的场景,它们是导致死锁或者goroutine泄露的罪魁祸首。
还有一个值得注意的点是,只要一个chan还有未读的数据,即使把它close掉,你还是可以继续把这些未读的数据消费完,之后才是读取零值数据。
思考题
1,有一道经典的使用Channel进行任务编排的题,你可以尝试做一下:有四个goroutine,编号为1、2、3、4。每秒钟会有一个goroutine打印出它自己的编号,要求你编写一个程序,让输出的编号总是按照1、2、3、4、1、2、3、4、……的顺序打印出来。
2,chanT是否可以给<-chanT和chan<-T类型的变量赋值?反过来呢?