思考并回答以下问题:
添加上下文Context为请求设置超时时间。
framework/context.go
1 | package framework |
controller.go
1 | package main |
封装一个自己的Context
代码结构图
在框架里,我们需要有更强大的Context,除了可以控制超时之外,常用的功能比如获取请求、返回结果、实现标准库的Context接口,也都要有。
我们首先来设计提供获取请求、返回结果功能。
先看一段未封装自定义Context的控制器代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38package main
import (
"encoding/json"
"net/http"
"strconv"
)
// 控制器
func Foo1(request *http.Request, response http.ResponseWriter) {
obj := map[string]interface{}{
"data": nil,
}
// 设置控制器 response 的 header 部分
response.Header().Set("Content-Type", "application/json")
// 从请求体中获取参数
foo := request.PostFormValue("foo")
if foo == "" {
foo = "10"
}
fooInt, err := strconv.Atoi(foo)
if err != nil {
response.WriteHeader(500)
return
}
// 构建返回结构
obj["data"] = fooInt
byt, err := json.Marshal(obj)
if err != nil {
response.WriteHeader(500)
return
}
// 构建返回状态,输出返回结构
response.WriteHeader(200)
response.Write(byt)
return
}
这段代码重点是操作调用了http.Request和http.ResponseWriter,实现WebService接收和处理协议文本的功能。但这两个结构提供的接口粒度太细了,需要使用者非常熟悉这两个结构的内部字段,比如response里设置Header和设置Body的函数,用起来肯定体验不好。
如果我们能将这些内部实现封装起来,对外暴露语义化高的接口函数,那么我们这个框架的易用性肯定会明显提升。什么是好的封装呢?再看这段有封装的代码:1
2
3
4
5
6
7
8
9
10
11
12// 控制器
func Foo2(ctx *framework.Context) error {
obj := map[string]interface{}{
"data": nil,
}
// 从请求体中获取参数
fooInt := ctx.FormInt("foo", 10)
// 构建返回结构
obj["data"] = fooInt
// 输出返回结构
return ctx.Json(http.StatusOK, obj)
}
你可以明显感受到封装性高的Foo2函数,更优雅更易读了。首先它的代码量更少,而且语义性也更好,近似对业务的描述:从请求体中获取foo参数,并且封装为Map,最后JSON输出。
思路清晰了,所以这里可以将request和response封装到我们自定义的Context中,对外提供请求和结果的方法,我们把这个Context结构写在框架文件夹的context.go文件中:1
2
3
4
5
6// 自定义 Context
type Context struct {
request *http.Request
responseWriter http.ResponseWriter
...
}
对request和response封装的具体实现,我们到第五节课封装的时候再仔细说。
然后是第二个功能,标准库的Context接口。
标准库的Context通用性非常高,基本现在所有第三方库函数,都会根据官方的建议,将第一个参数设置为标准Context接口。所以我们封装的结构只有实现了标准库的Context,才能方便直接地调用。
到底有多方便,我们看使用示例:1
2
3
4
5
6
7
8
9func Foo3(ctx *framework.Context) error {
rdb := redis.NewClient(&redis.Options{
Addr: "localhost:6379",
Password: "", // no password set
DB: 0, // use default DB
})
return rdb.Set(ctx, "key", "value", 0).Err()
}
这里使用了go-redis库,它每个方法的参数中都有一个标准Context接口,这让我们能将自定义的Context直接传递给rdb.Set。
只需要调用刚才封装的request中的Context的标准接口就行了,继续在context.go中进行补充:1
2
3
4
5
6
7func (ctx *Context) BaseContext() context.Context {
return ctx.request.Context()
}
func (ctx *Context) Done() <-chan struct{} {
return ctx.BaseContext().Done()
}
context.go完整代码
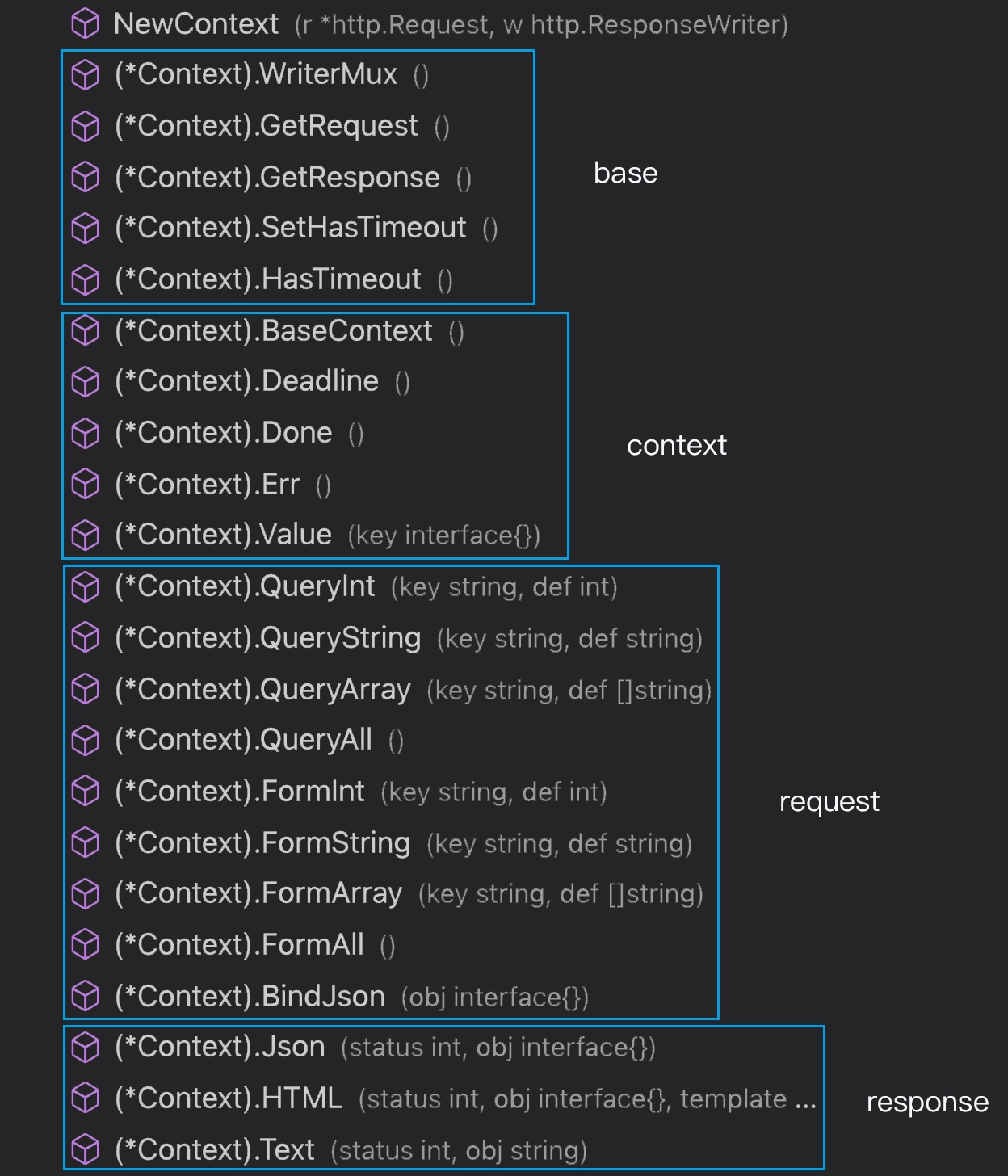
Context最终需要提供四类功能函数:
- base封装基本的函数功能,比如获取
http.Request结构 - context实现标准Context接口
- request封装了
http.Request的对外接口 - response封装了
http.ResponseWriter对外接口
函数列表
有了我们自己封装的Context之后,控制器就非常简化了。把框架定义的ControllerHandler放在框架目录下的controller.go文件中:1
type ControllerHandler func(c *Context) error
把处理业务的控制器放在业务目录下的controller.go文件中:1
2
3
4
5func FooControllerHandler(ctx *framework.Context) error {
return ctx.Json(200, map[string]interface{}{
"code": 0,
})
}
为单个请求设置超时
如何使用自定义Context设置超时呢?
1,继承request的Context,创建出一个设置超时时间的Context;
2,创建一个新的Goroutine来处理具体的业务逻辑;
3,设计事件处理顺序,当前Goroutine监听超时时间Context的Done()事件,和具体的业务处理结束事件,哪个先到就先处理哪个。
第一步生成一个超时的Context:
controller.go
1 | durationCtx, cancel := context.WithTimeout(c.BaseContext(), time.Duration(1*time.Second)) |
这里为了最终在浏览器做验证,我设置超时事件为1s,这样最终验证的时候,最长等待1s就可以知道超时是否生效。
第二步创建一个新的Goroutine来处理业务逻辑:1
2
3
4
5
6
7
8
9
10
11finish := make(chan struct{}, 1)
go func() {
...
// 这里做具体的业务
time.Sleep(10 * time.Second)
c.Json(200, "ok")
...
// 新的 goroutine 结束的时候通过一个 finish 通道告知父 goroutine
finish <- struct{}{}
}()
为了最终的验证效果,我们使用time.Sleep将新Goroutine的业务逻辑事件人为往后延迟了10s,再输出“ok”,这样最终验证的时候,效果比较明显,因为前面的超时设置会在1s生效了,浏览器就有表现了。
到这里我们这里先不急着进入第三步,还有错误处理情况没有考虑到位。这个新创建的Goroutine如果出现未知异常怎么办?需要我们额外捕获吗?
其实在Golang的设计中,每个Goroutine都是独立存在的,父Goroutine一旦使用Go关键字开启了一个子Goroutine,父子Goroutine就是平等存在的,他们互相不能干扰。而在异常面前,所有Goroutine的异常都需要自己管理,不会存在父Goroutine捕获子Goroutine异常的操作。
所以切记:在Golang中,每个Goroutine创建的时候,我们要使用defer和recover关键字为当前Goroutine捕获panic异常,并进行处理,否则,任意一处panic就会导致整个进程崩溃!
回看第二步,做完具体业务逻辑就结束是不行的,还需要处理panic。所以这个Goroutine应该要有两个channel对外传递事件:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19// 这个channal负责通知结束
finish := make(chan struct{}, 1)
// 这个channel负责通知panic异常
panicChan := make(chan interface{}, 1)
go func() {
// 这里增加异常处理
defer func() {
if p := recover(); p != nil {
panicChan <- p
}
}()
// 这里做具体的业务
time.Sleep(10 * time.Second)
c.Json(200, "ok")
...
// 新的goroutine结束的时候通过一个finish通道告知父goroutine
finish <- struct{}{}
}()
现在第二步才算完成了,我们继续写第三步监听。使用select关键字来监听三个事件:异常事件、结束事件、超时事件。1
2
3
4
5
6
7
8
9
10
11
12
13
14select {
// 监听 panic
case p := <-panicChan:
...
c.Json(500, "panic")
// 监听结束事件
case <-finish:
...
fmt.Println("finish")
// 监听超时事件
case <-durationCtx.Done():
...
c.Json(500, "time out")
}
接收到结束事件,只需要打印日志,但是,在接收到异常事件和超时事件的时候,我们希望告知浏览器前端“异常或者超时了”,所以会使用c.Json来返回一个字符串信息。
三步走到这里就完成了对某个请求的超时设置,你可以通过go build、go run尝试启动下这个服务。如果你在浏览器开启一个请求之后,浏览器不会等候事件处理10s,而在等待我们设置的超时事件1s后,页面显示“timeout”就结束这个请求了,就说明我们为某个事件设置的超时生效了。
边界场景
边界场景有两种可能:
1,异常事件、超时事件触发时,需要往responseWriter中写入信息,这个时候如果有其他Goroutine也要操作responseWriter,会不会导致responseWriter中的信息出现乱序?
2,超时事件触发结束之后,已经往responseWriter中写入信息了,这个时候如果有其他Goroutine也要操作responseWriter,会不会导致responseWriter中的信息重复写入?
第一个问题,我们要保证在事件处理结束之前,不允许任何其他Goroutine操作responseWriter,这里可以使用一个锁(sync.Mutex)对responseWriter进行写保护。
context.go
1 | type Context struct { |
controller.go
1 | func FooControllerHandler(c *framework.Context) error { |
第二个问题,可以设计一个标记,当发生超时的时候,设置标记位为true,在Context提供的response输出函数中,先读取标记位;当标记位为true,表示已经有输出了,不需要再进行任何的response设置了。
context.go
1 | func (ctx *Context) SetHasTimeout() { |
controller.go
1 | func FooControllerHandler(c *framework.Context) error { |
剩下的验证部分,我们写一个简单的路由函数,将这个控制器路由在业务文件夹中创建一个route.go:1
2
3
4func registerRouter(core *framework.Core) {
// 设置控制器
core.Get("foo", FooControllerHandler)
}
并修改main.go:1
2
3
4
5
6func main() {
...
// 设置路由
registerRouter(core)
...
}
context标准库设计思路
如何控制超时,context标准库的解决思路是:在整个树形逻辑链条中,用上下文控制器Context,实现每个节点的信息传递和共享。
具体操作是:用Context定时器为整个链条设置超时时间,时间一到,结束事件被触发,链条中正在处理的服务逻辑会监听到,从而结束整个逻辑链条,让后续操作不再进行。
1 | go doc context | grep "^func" |
1 | // 创建退出Context |
其中,WithCancel直接创建可以操作退出的子节点,WithTimeout为子节点设置了超时时间(还有多少时间结束),WithDeadline为子节点设置了结束时间线(在什么时间结束)。
但是这只是表层功能的不同,其实这三个库函数的本质是一致的。怎么理解呢?
我们先通过go doc context | grep "^type",搞清楚Context的结构定义和函数句柄,再来解答这个问题。1
2
3
4
5
6
7
8type Context interface {
// 当Context被取消或者到了deadline,返回一个被关闭的channel
Done() <-chan struct{}
...
}
// 函数句柄
type CancelFunc func()
只理解核心的Done()方法和CancelFunc这两个函数就可以了。
在树形逻辑链条上,一个节点其实有两个角色:一是下游树的管理者;二是上游树的被管理者,那么就对应需要有两个能力:
- 一个是能让整个下游树结束的能力,也就是函数句柄CancelFunc;
- 另外一个是在上游树结束的时候被通知的能力,也就是Done()方法。同时因为通知是需要不断监听的,所以Done()方法需要通过channel作为返回值让使用方进行监听。
看官方代码示例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25package main
import (
"context"
"fmt"
"time"
)
const shortDuration = 1 * time.Millisecond
func main() {
// 创建截止时间
d := time.Now().Add(shortDuration)
// 创建有截止时间的 Context
ctx, cancel := context.WithDeadline(context.Background(), d)
defer cancel()
// 使用 select 监听 1s 和有截止时间的 Context 哪个先结束
select {
case <-time.After(1 * time.Second):
fmt.Println("overslept")
case <-ctx.Done():
fmt.Println(ctx.Err())
}
}
主线程创建了一个1毫秒结束的定时器Context,在定时器结束的时候,主线程会通过Done()函数收到事件结束通知,然后主动调用函数句柄cancelFunc来通知所有子Context结束(这个例子比较简单没有子Context)。
打个更形象的比喻,CancelFunc和Done方法就像是电话的话筒和听筒,话筒CancelFunc,用来告诉管辖范围内的所有Context要进行自我终结,而通过监听听筒Done方法,我们就能听到上游父级管理者的终结命令。
总之,CancelFunc是主动让下游结束,而Done是被上游通知结束。
WithCancel/WithDeadline/WithTimeout的本质就是“通过定时器来自动触发终结通知”,WithTimeout设置若干秒后通知触发终结,WithDeadline设置未来某个时间点触发终结。
对应到Context代码中,它们的功能就是:为一个父节点生成一个带有Done方法的子节点,并且返回子节点的CancelFunc函数句柄。
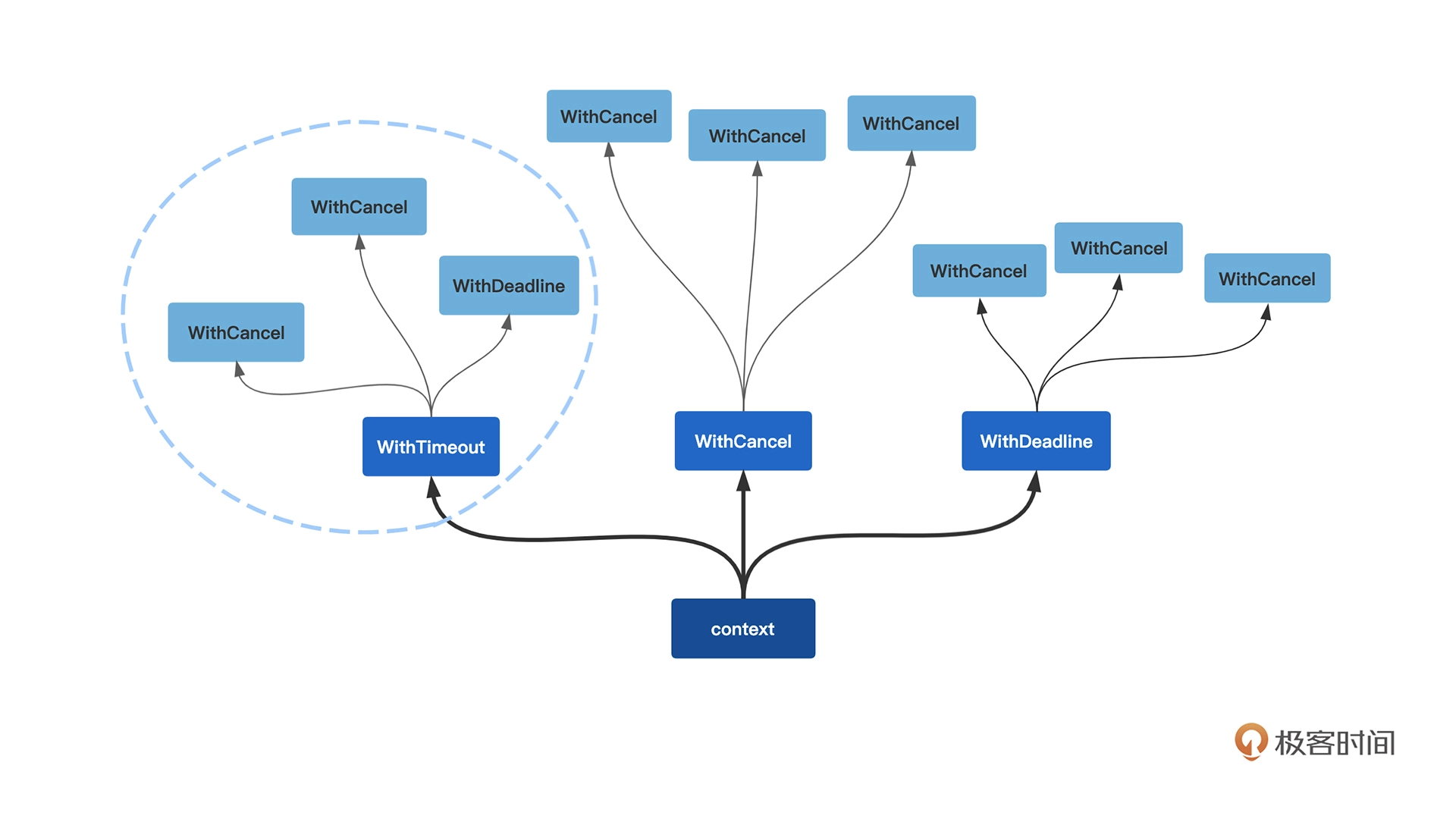
Context的使用会形成一个树形结构,下游指的是树形结构中的子节点及所有子节点的子树,而上游指的是当前节点的父节点。比如图中圈起来的部分,当WithTimeout调用CancelFunc的时候,所有下游的With系列产生的Context都会从Done中收到消息。
Context是怎么产生的
Context在哪里产生?它的上下游逻辑是什么?
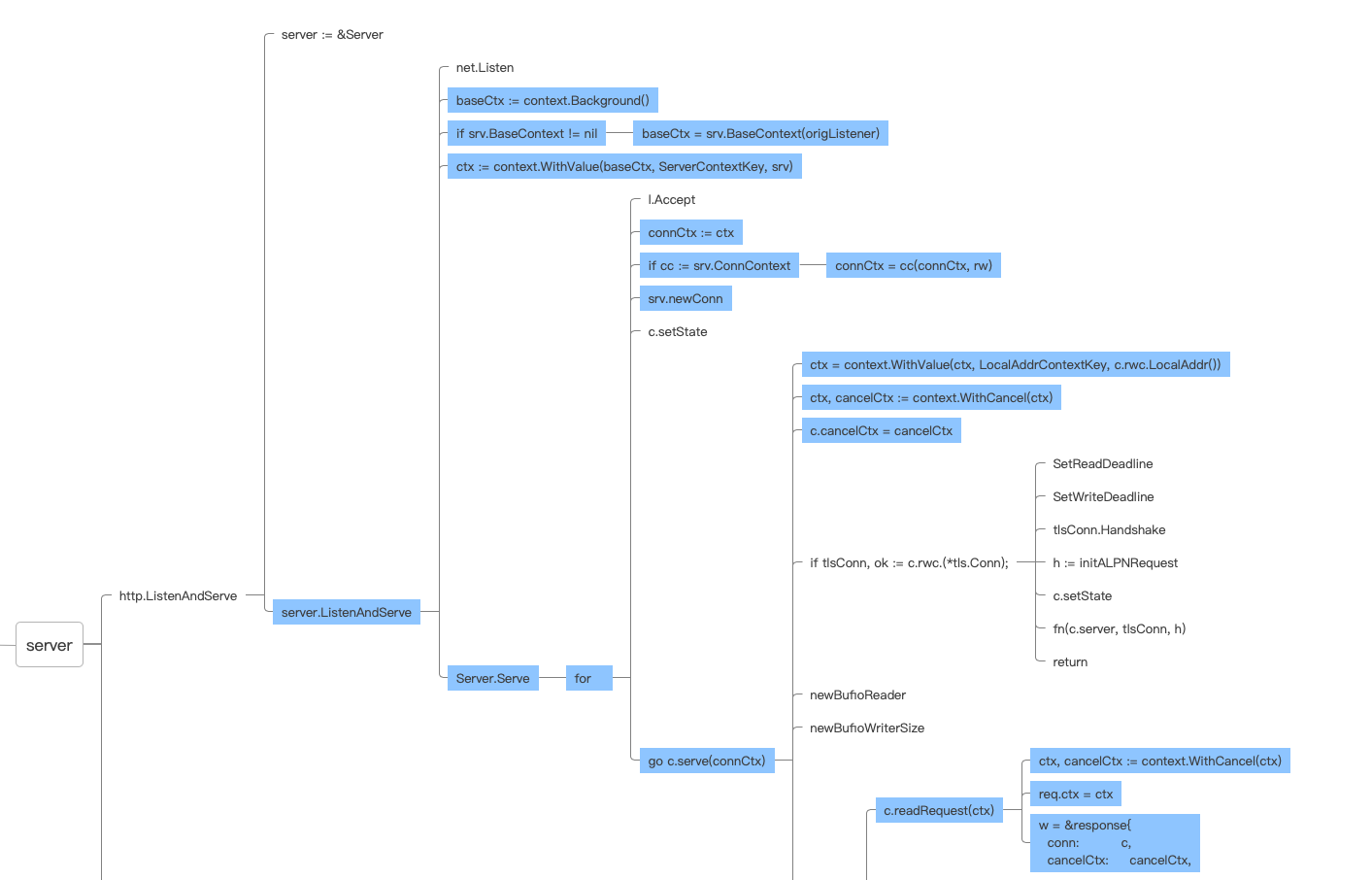
从图中最后一层的代码req.ctx=ctx中看到,每个连接的Context最终是放在request结构体中的。
而且这个时候,Context已经有多层父节点。因为,在代码中,每执行一次WithCancel、WithValue,就封装了一层Context,我们通过这一张流程图能清晰看到最终Context的生成层次。
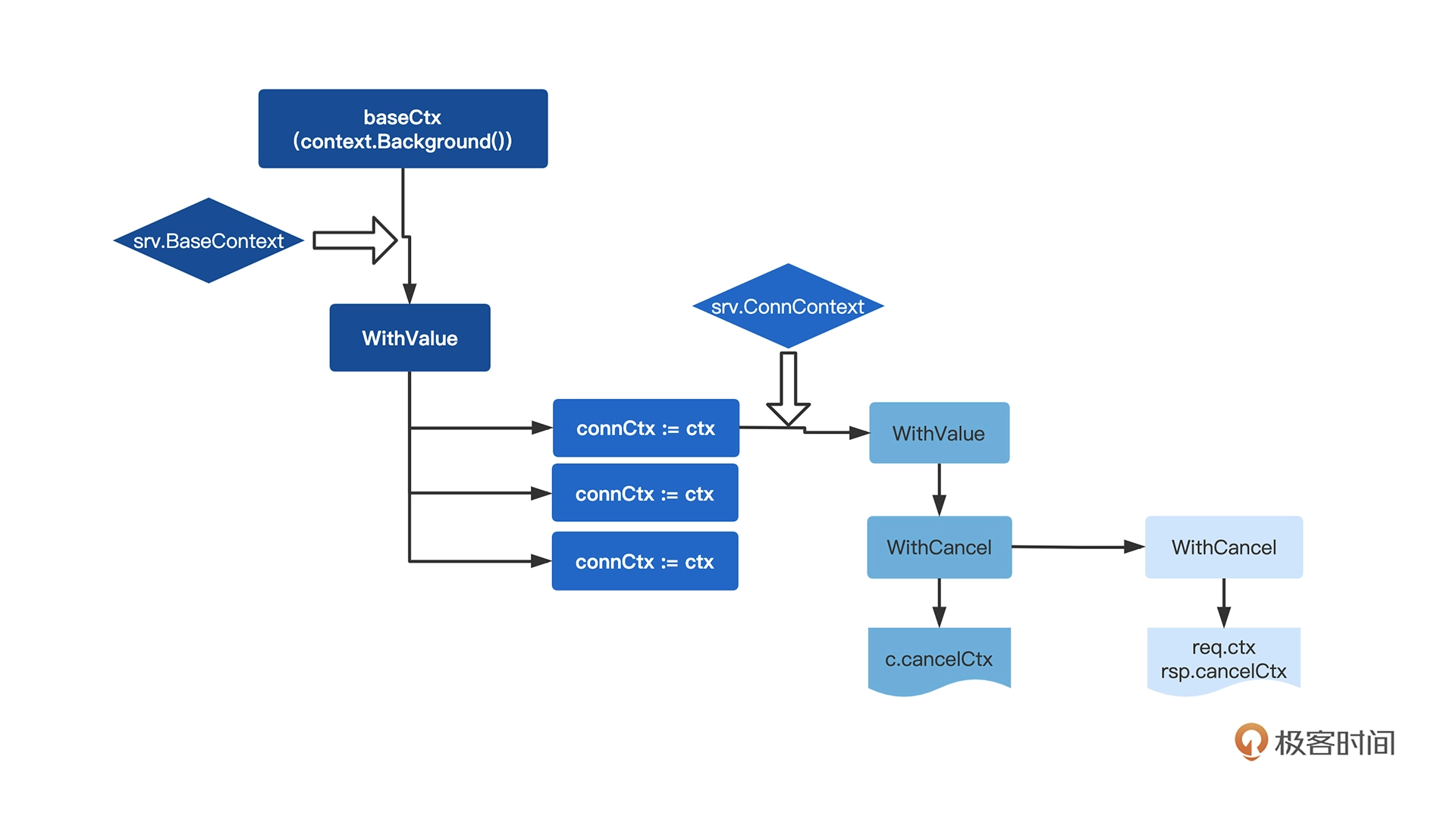
每个连接的Context都是基于baseContext复制来的。对应到代码中就是,在为某个连接开启Goroutine的时候,为当前连接创建了一个connContext,这个connContext是基于server中的Context而来,而server中Context的基础就是baseContext。
生成最终的Context的流程中,net/http设计了两处可以注入修改的地方,都在Server结构里面,一处是BaseContext,另一处是ConnContext。
- BaseContext是整个Context生成的源头,如果我们不希望使用默认的context.Backgroud(),可以替换这个源头。
- 而在每个连接生成自己要使用的Context时,会调用ConnContext,它的第二个参数是net.Conn,能让我们对某些特定连接进行设置,比如要针对性设置某个调用IP。
1 | type Server struct { |
最后,我们回看一下req.ctx是否能感知连接异常。
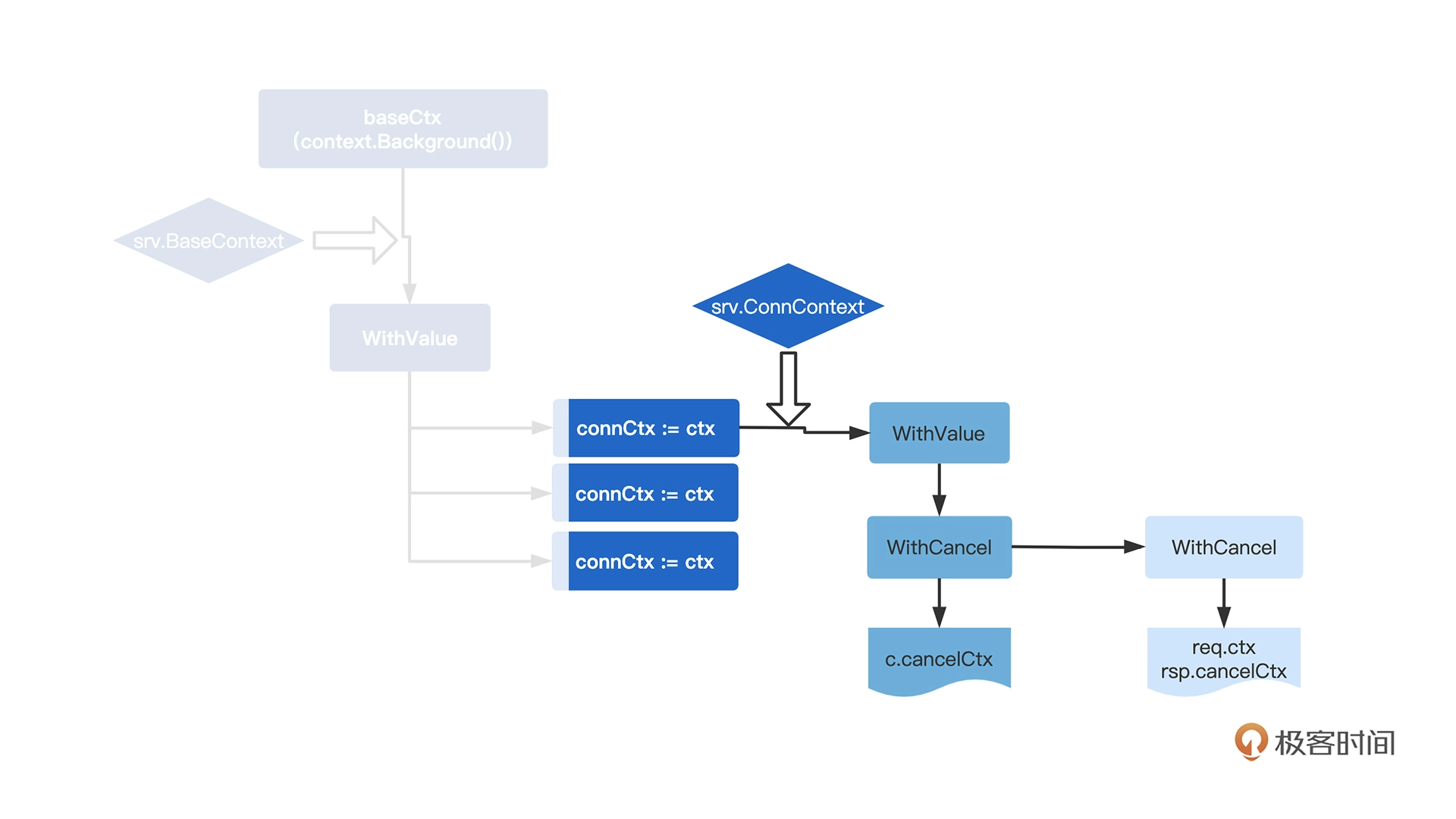
是可以的,因为链条中一个父节点为CancelContext,其cancelFunc存储在代表连接的conn结构中,连接异常的时候,会触发这个函数句柄。
小结
定义了一个属于自己框架的Context,它有两个功能:在各个Goroutine间传递数据;控制各个Goroutine,也就是是超时控制。
这个自定义Context结构封装了net/http标准库主逻辑流程产生的Context,与主逻辑流程完美对接。它除了实现了标准库的Context接口,还封装了request和response的请求。你实现好了Context之后,就会发现它跟百宝箱一样,在处理具体的业务逻辑的时候,如果需要获取参数、设置返回值等,都可以通过Context获取。
封装后,我们通过三步走为请求设置超时,并且完美地考虑了各种边界场景。
思考题
在context库的官方文档中有这么一句话:1
2
3Do not store Contexts inside a struct type;
instead, pass a Context explicitly to each function that needs it.
The Context should be the first parameter.
大意是说建议我们设计函数的时候,将Context作为函数的第一个参数。你能理解官方为什么如此建议,有哪些好处?可以结合你的工作经验,说说自己的看法。